
Pour être « data-centric » une organisation doit d’abord être « metadata-centric ». Et pour être « metadata-centric » elle doit être « catalog-centric » …
Dans l’une de nos précédentes publications (« Pour gouverner vos données gérez vos métadonnées »), nous avons insisté sur le rôle central que jouent les métadonnées dans la mise en place d’une Gouvernance des données. Les organisations ayant investi dans la gestion des métadonnées constatent des progrès significatifs dans leur capacité à exploiter rapidement des données de qualité, à condition qu’elles se soient préalablement dotées d’un outillage adapté…
Définition et fonctionnalités d’un catalogue de données
Un catalogue de données est un ensemble de métadonnées, combiné à des fonctionnalités de gestion et de recherche, qui aide les utilisateurs du Système d’Information (acteurs des métiers et de l’informatique) à trouver les données dont ils ont besoin au quotidien. Les métadonnées constituent une base de connaissances qui facilite la découverte des informations existantes dans le SI et fournit un appui à l’évaluation de la pertinence de la donnée pour un cas d’utilisation défini.
Une organisation est amenée à mettre en place un catalogue de données pour de multiples raisons. Mais avant d’aborder les principaux contextes d’utilisation du Data Catalog, commençons par donner un bref aperçu des fonctionnalités proposées par les solutions logicielles disponibles sur le marché.
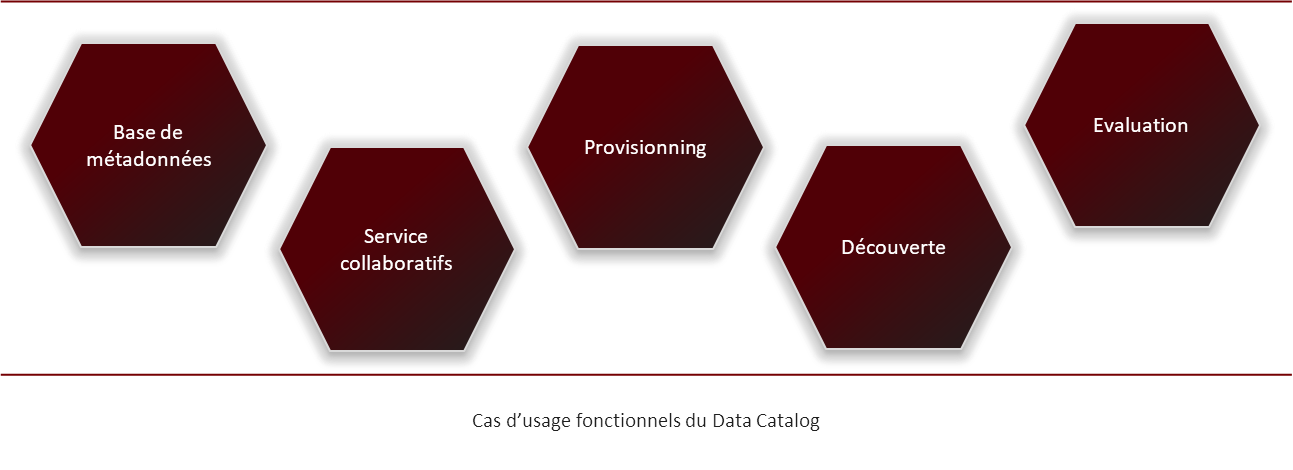
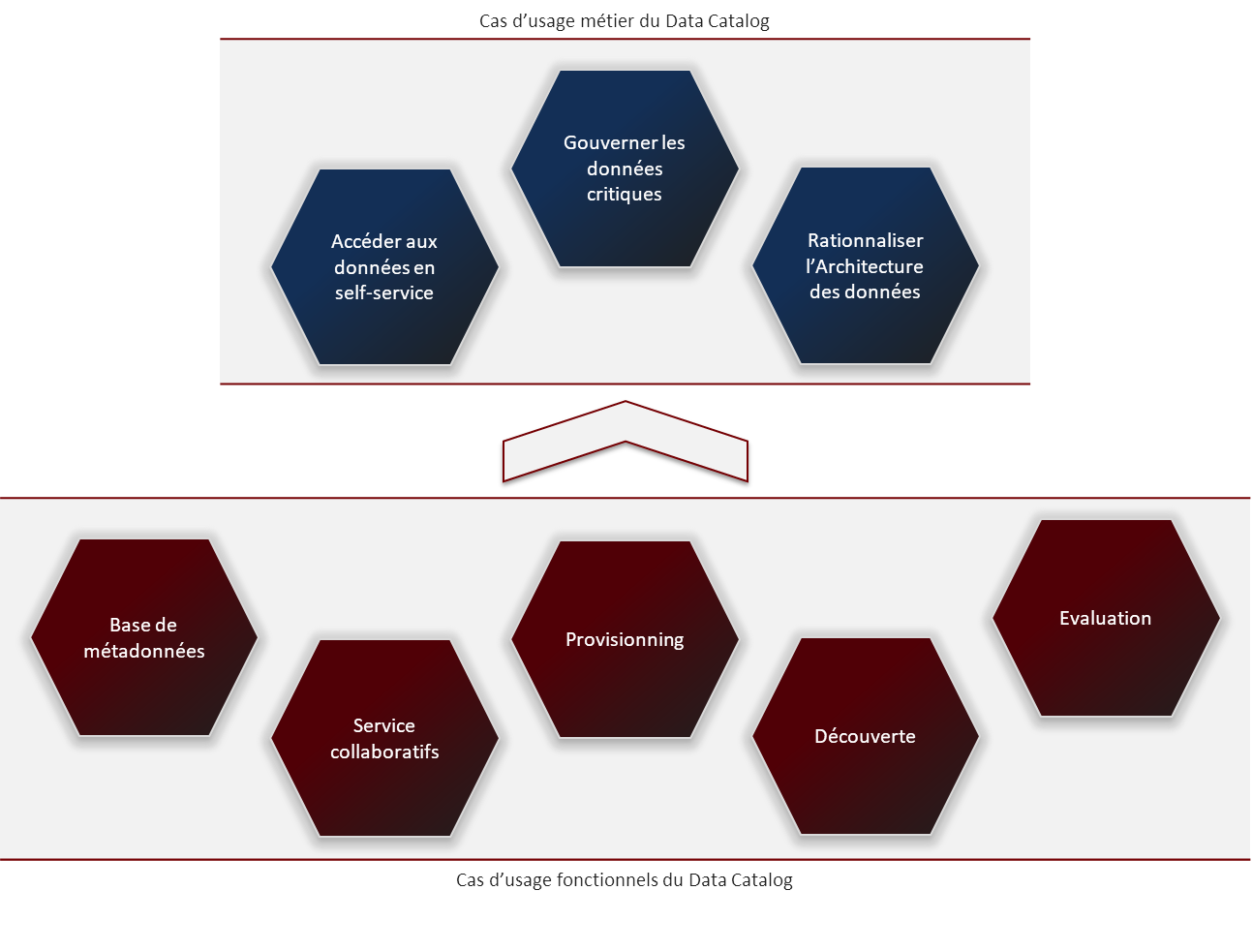
Actuellement, la plupart des solutions de Data Catalog s’articulent autour de cinq ensembles de services :
- La base des métadonnées qui identifie et décrit le patrimoine de données de l’entreprise. Cette base de métadonnées est l’élément fondamental du catalogue. La faculté d’ajouter des métadonnées personnalisées est essentielle. Elle garantit l’évolutivité du catalogue et permet de répondre à des besoins qui ne sont pas (et ne peuvent pas) être connus au moment de sa mise en place.
- Les services permettant d’assurer le provisioning. Ils sont utilisés afin d’ajouter de nouvelles entrées dans le catalogue et pour les enrichir avec des métadonnées. Le processus peut être manuel ou automatisé (depuis les sources de données existantes). L’approvisionnement manuel est nécessaire pour aboutir à un résultat de qualité. Les utilisateurs renseignent des métadonnées métier axées sur la définition et la classification de la donnée. Ils produisent également des évaluations sur le potentiel d’utilisation de la donnée.
- Les services de collaboration. La mise en place de workflows collaboratifs permet de mobiliser l’intelligence collective de l’organisation et de coordonner les contributions des différents acteurs sur la globalité du cycle de vie de la métadonnée. Ces services contribuent notamment à collecter la connaissance « tribale » que possèdent les métiers sur leurs données. On emploie souvent le terme de « crowdsourcing » pour désigner ce processus de production participative.
- La découverte des jeux de données. Elle inclut la recherche par facettes (multicritère), par mots clés et par termes métier. Des capacités de recherche en langage naturel peuvent également être proposées. La disponibilité d’indicateurs de pertinence et de fréquence d’utilisation facilite le processus d’évaluation des sous-ensembles de données.
- L’évaluation des jeux de données. Le choix des collections de données appropriées dépend non seulement des possibilités de recherche mais encore de la capacité à évaluer la pertinence de ces collections vis-à-vis d’un objectif d’utilisation, sans avoir à télécharger ou acquérir des données au préalable. Le processus d’évaluation s’appuie sur des fonctionnalités permettant de prévisualiser un ensemble de données, de voir toutes les métadonnées associées, de consulter les avis et commentaires des utilisateurs et des curateurs, et d’accéder à des indicateurs de qualité de la donnée. Certaines solutions ont recours à l’IA et au machine learning pour mettre en avant tel ou tel jeu de données, en fonction du contexte d’utilisation envisagé. L’accès en consultation à un échantillon des données participe au processus d’évaluation. Il doit être possible, dans le respect des réglementations sur la protection des données personnelles, moyennant l’application de règles d’anonymisation.
Les cas d’usage métier du Data Catalog
Accéder aux données en self-service
En l’absence d’un catalogue de données, les Data Analysts travaillent sans réelle visibilité sur les sources à disposition, le contenu de ces sources, ainsi que sur la qualité et l’utilité de chacune d’entre elles. L’incapacité à exploiter des métadonnées a un impact direct sur la productivité des spécialistes de la donnée. Les enquêtes tendent à démontrer que, dans un tel contexte, ces derniers ne consacrent que 20 % de leur temps de travail à l’analyse des données. Les 80% restants, ils le passent dans des activités de recherche et de préparation. Ces travaux sont certes nécessaires mais ils se font au détriment du temps pris pour réaliser les analyses. Ils ne produisent pas de valeur directement exploitable par les métiers. Dans certains cas, les collaborateurs peuvent aller jusqu’à recréer des données existantes, simplement parce qu’ils n’ont pas pu ou pas su y avoir accès.
Le déploiement d’un Data Catalog est une réponse pratique à la nécessité d’améliorer la visibilité et l’usabilité de la donnée consommée par les différents acteurs de l’organisation. Elle doit permettre d’inverser favorablement les chiffres énoncés plus haut : 80% de temps consacré à la consommation de données pertinentes et de qualité, contre 20% de temps pris pour les préparer et les mettre à disposition.
Le recours au catalogue pour faciliter la découverte et l’utilisation des données à des fins d’analyse et de reporting constitue le cas d’utilisation le plus fréquemment mis en avant par les fournisseurs de solutions. Grâce au catalogue, les Data Analysts sont en mesure de trouver la donnée qui va leur être utile au moment où ils en ont besoin.
Gouverner les données critiques
Dans l’un de nos précédents articles (« Pour gouverner vos données gérez vos métadonnées »), nous avons expliqué le rôle central que tient la gestion des métadonnées (et plus particulièrement des métadonnées métier) dans la Gouvernance de la donnée. C’est la même idée qui est soutenue ici mais à travers le prisme du Data Catalog. Nous employons volontairement le qualificatif de « données critiques » afin d’insister sur la nécessité d’adopter une approche différenciée en fonction de la valeur que représente la donnée pour l’organisation. Cette notion fera l’objet d’un prochain billet. Pour l’instant, admettons simplement que les données critiques sont celles pour lesquelles les exigences en matière de qualité et de protection sont les plus élevées.
L’utilisation d’une solution de Data Catalog permet de répondre aux enjeux suivants :
- Identifier les données dont le cycle de vie sera soumis à des règles de gestion particulières.
- En préalable, à tout autre action, aligner les différents acteurs sur les définitions et la sémantique de ces données.
- Documenter et partager les règles de gestion à fort impact métier, de même que les contrôles à opérer sur le cycle de vie de la donnée (quelles sont les règles qui garantissent la validité et l’exploitabilité de la donnée ? sous quelles conditions la donnée peut-elle être partagée ? archivée ? …).
- Documenter les exigences de qualité requises pour l’application des règles métier. Par exemple : « disposer d’une adresse valide pour facturer un client implique que tous les champs qui composent l’adresse soit renseignés et vérifiés auprès d’une autorité compétente ».
- Collecter et restituer des appréciations concernant la qualité de la donnée afin d’augmenter sa valeur d’usage.
- Définir les rôles et responsabilités impliqués dans la gestion de la donnée (le Who’s Who de la data). La gestion et l’analyse des données sont en fin de compte des activités humaines. Par conséquent, l’organisation doit référencer les individus qui sont des acteurs du cycle de vie de la donnée et documenter leurs périmètres d’action respectifs (producteur, consommateur, propriétaire, référent, sachant métier, intendant…).
- Identifier et classifier les données privées ou sensibles, concernées par les différentes réglementations.
- Elaborer et maintenir le registre des traitements opérés sur les données à caractère personnel afin de faciliter les analyses d’impact relatives à la protection des données (Privacy Impact Assessement).
Rationaliser l’Architecture des données
Le catalogue des données est le point d’ancrage à partir duquel l’organisation va chercher à rationaliser l’architecture de ses données. C’est une opportunité qui va se manifester durant la réalisation des projets informatiques.
- Au moment de la conception d’une solution, le glossaire des termes métier va contribuer à améliorer la qualité du produit. L’équipe projet va en effet élaborer son modèle en s’alignant sur des concepts et des définitions éprouvés et partagés à l’échelle de l’Enterprise. Le modèle produit sera plus robuste et les flux d’échange seront plus faciles à mettre en œuvre. La cartographie des sources disponibles dans le catalogue permettra de déterminer si certaines des données requises existent déjà dans un autre système et si elles peuvent être exploitées par la nouvelle solution ; évitant ainsi la création d’un nouveau silo de données.
- Durant les phases de reprise des données, le catalogue permettra d’identifier parmi les sources potentielles celle qui est la plus apte à répondre aux exigences de qualité de la solution en cours de construction ; à condition toutefois que des informations concernant la qualité des sources aient été intégrées dans le périmètre de gestion du catalogue. Ainsi, l’utilisation du Data Catalog limitera le risque de réutilisation d’une source de données peu fiable et susceptible de produire de mauvais résultats lors de la migration.
- Pour la mise en œuvre d’une initiative de Master Data Management (MDM). Les Master Data sont celles qui sont le plus fortement disséminées dans le SI. Dans les projets MDM l’enjeu de qualité se conjugue à des objectifs de contrôle sur la propagation de la donnée. On doit sélectionner les applications autorisées à produire la donnée et déterminer les exigences de qualité qui conditionnent sa diffusion vers les applications qui la consomment. Il faut également définir et affecter les rôles métier nécessaires aux contrôles exercés sur le cycle de vie de la donnée (qui est responsable de la qualité et de la validation de la donnée produite ? qui veille à l’application des règles de propagation ? qui est responsable du traitement des doublons et de la définition des golden records ? …). Le catalogue permet de centraliser les réponses à toutes ces questions et de les rendre facilement accessibles aux différents acteurs.
La nécessité d’une approche centralisée et outillée
L’une des principales raisons pour lesquelles on doit gérer les métadonnées est que les données ont été fortement disséminées dans les applications qui composent le SI, avec les conséquences que l’on connaît : inefficience organisationnelle, difficulté à prendre les bonnes décisions et à engager les bonnes actions. Et l’une des raisons qui militent en faveur d’un catalogue centralisé est que les métadonnées ont également été disséminées (avec d’ailleurs les mêmes conséquences).
Beaucoup de métadonnées existent au sein même des applicatifs qui stockent les données. Mais il s’agit là d’informations qui ne peuvent être directement utilisées par les acteurs métier. Les définitions, lorsqu’elles existent, sont locales à l’application. Elles n’ont pas été validées pour un usage à l’échelle de l’entreprise. Les métadonnées hébergées dans les solutions métier ne peuvent en aucun cas rendre compte de l’utilité potentielle de la donnée pour un cas usage spécifique. La prolifération des catalogues de données se traduit par des silos de métadonnées redondantes et possiblement incohérentes entre elles. Ces catalogues locaux sont difficilement exploitables.
Ce dont nous avons réellement besoin, c’est d’un catalogue commun, offrant une vision unifiée sur les métadonnées de l’organisation. Seule une approche centralisée et intégrée répond aux enjeux de Gouvernance de la donnée (gérer l’information comme un actif stratégique), car c’est la seule qui permet de partager efficacement la connaissance sur les données et d’augmenter leur valeur au fil du temps.
La question qui se pose alors est de savoir s’il est envisageable de gérer manuellement son catalogue de données, sous Excel ou avec tout autre solution de type bureautique. La réponse est catégoriquement non. Car il faut à la fois convaincre de l’utilité de la démarche et pouvoir absorber l’augmentation de la charge de travail qui va accompagner l’extension du périmètre d’utilisation du catalogue. Ce double objectif ne peut être atteint que si l’organisation se dote d’une solution offrant un panel de services spécifiquement élaborés pour une gestion collaborative du cycle de vie de la métadonnée. Une implémentation réalisée sous Excel, aussi sophistiquée soit-elle, ne répondra pas à l’ensemble du cahier des charges (les 5 cas d’usage fonctionnels présentés plus haut).
Conclusion
La gestion des données a radicalement évolué au cours de ces dernières années. Il ne s’agit plus d’un territoire réservé aux professionnels de l’IT. Les acteurs métier ont compris que la donnée n’est pas seulement un produit de l’informatique mais qu’il s’agit bien d’un actif stratégique dont ils peuvent tirer profit. Cependant, avec l’arrivée du Big Data, les entreprises doivent faire face à de nouveaux défis qui rendent la gestion des données plus compliquée. Dans de nombreuses situations, la donnée n’est pas utilisée au-delà de son contexte d’origine. Son potentiel de création de valeur n’est pas suffisamment exploité.
La meilleure manière de résoudre ce problème consiste certainement à déployer un catalogue de données. La finalité d’un tel catalogue est d’aider ses utilisateurs à découvrir et à comprendre des données potentiellement pertinentes qu’ils ne connaissent pas bien ou qu’ils ne connaissaient pas auparavant. Le Data Catalog est une solution logicielle conçue pour gérer la connaissance sur les données. En favorisant la collaboration de tous, il s’impose comme l’élément fédérateur de la gestion des données.
Par conséquent, pas de gestion des données sans métadonnées et pas de gestion des métadonnées sans catalogue de données.
Redsen Consulting aide les organisations à évaluer leur niveau de maturité dans le domaine du Data Management ! Remplissez le formulaire en ligne Audit Quick Start Data Management et bénéficiez d’un diagnostic gratuit réalisé par nos experts.




